本地搭建 DeepSeek-R1 大模型:结合 Ollama、AnythingLLM 和 Dify
随着大语言模型的快速发展,越来越多的开源工具和平台让用户能够在本地搭建和运行类似 GPT-3、GPT-4 的大语言模型。DeepSeek-R1 是一种开源的大语言模型,它支持自然语言处理任务,具有强大的推理和生成能力。结合 Ollama、AnythingLLM 和 Dify,我们可以轻松地在本地搭建一个完善的 LLM 环境,并通过 API 或 Web 接口进行交互和集成。
搭建流程概览
在这篇文章中,我们将涉及以下几个步骤:
- 安装和配置 Ollama
- 配置 AnythingLLM 来管理模型
- 使用 Dify 部署和集成模型
环境准备
在开始之前,确保你的机器具备以下环境:
- 操作系统:macOS 或 Linux(Windows 系统可以通过 WSL 来实现)
- Docker:用于管理容器化的应用和服务
- Ollama、AnythingLLM 和 Dify:需要安装这些工具和相关依赖
步骤详解
1. 安装 Ollama
Ollama 是一个本地 LLM 管理工具,它支持多个大语言模型的集成和运行。你可以使用 Ollama 来下载并管理 DeepSeek-R1 模型。
安装 Ollama: 首先,前往 Ollama 官方网站下载适用于你的操作系统的安装包: https://ollama.com/download
下载完成后,按照安装指南进行安装。
对于Linux用户,可以使用以下命令一键安装:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,验证是否成功:
ollama --version使用anythingLLM或dify来访问ollama的HTTP API,访问地址为:127.0.0.1:11434
有时候需要修改服务配置
# 编辑ollama服务配置文件
vim /etc/systemd/system/ollama.service
# 编写完服务配置后重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama编写服务配置信息,其中OLLAMA_MODELS环境变量可以指定ollama的模型存储路径,OLLAMA_HOST=0.0.0.0:11434表示接口在11434端口监听局域网的请求,配置完后,可以通过局域网IP:11434来访问ollama的接口,直接浏览器访问会出现Ollama is running的提示
需要根据相关路径来修改下面配置文件
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_MODELS=/hdd/ollama/.ollama/models"
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=default.target启动和运行模型
ollama run MODEL [PROMPT] [flags]
# 例如运行deepseek-r1:7b
ollama run deepseek-r1:7b更多模型地址可以访问ollama的模型列表页面:https://ollama.com/search
ollama 模型下载小技巧:在实践当中发现,使用ollama run下载模型时,下载速度会越来越慢(不知道是不是我网络的问题),可以通过ctrl+c中断后再重新运行ollama run,这样可以恢复速度
查看正在运行的模型
ollama list运行后,会列出正在运行的模型
NAME ID SIZE MODIFIED
deepseek-r1:7b 0a8c26691023 4.7 GB 8 minutes ago
deepseek-r1:32b 38056bbcbb2d 19 GB 32 minutes agoTips: 如果启动后无法通过访问11434端口访问
可能的原因有:
- 防火墙禁止访问11434端口,需开启
ubuntu下开启11434端口
sudo ufw allow 114342. AnythingLLM
AnythingLLM 是一个非常适合管理大语言模型的工具,它可以帮助我们在本地运行 LLM、设置 API 接口以及进行模型的调用。
AnythingLLM Desktop 是使用 AnythingLLM 最简单的方式。
安装 AnythingLLM Desktop
进入下载页面,下载安装包安装即可:https://anythingllm.com/desktop
使用docker安装服务器版的AnythingLLM
export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
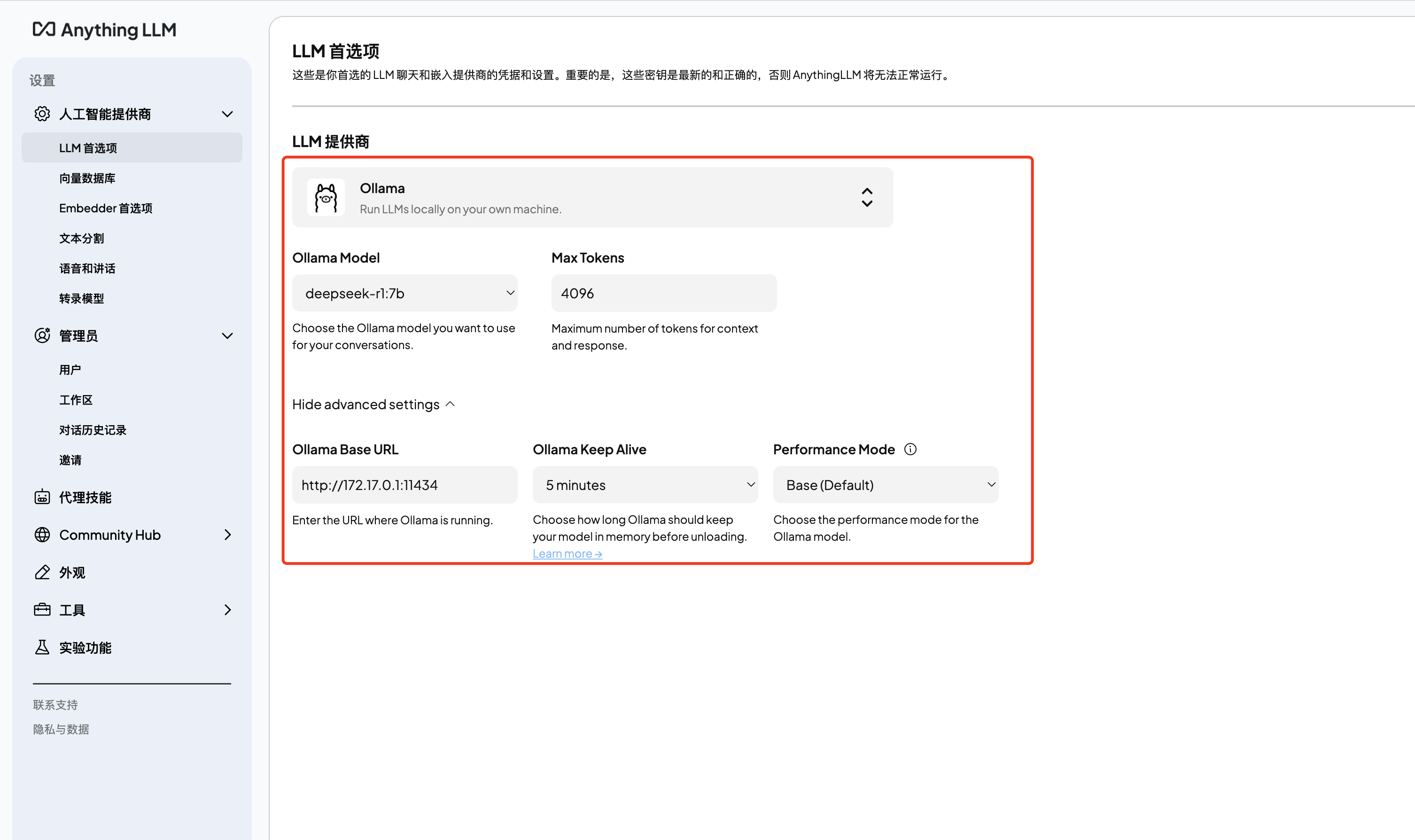
mintplexlabs/anythingllm配置信息(点击图片可查看大图):其中Ollama Base URL需要根据服务器实际IP填写
Tips: docker不能下载镜像怎么办?
可以找个腾讯云/阿里云的服务器,用docker pull下载下来镜像后,将镜像打包下载下来,再用docker load导入镜像
sudo docker save -o anythingllm.tar mintplexlabs/anythingllm:latest
sudo docker load --input anythingllm.tar或者尝试下面的docker hub镜像:
修改/etc/docker/daemon.json文件(没有则新建一个),添加下面的内容
{
"registry-mirrors": [
"https://docker.1panel.dev",
"https://docker.1ms.run"
]
}修改完后,重启docker服务
sudo systemctl daemon-reload
sudo systemctl restart docker3. Dify 部署
Dify 是一个生成式 AI 应用创新引擎。
开源的 LLM 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。
安装 Dify:
git clone https://github.com/langgenius/dify.git
cd dify
cd docker
cp .env.example .env
docker compose up -d运行后,您可以通过浏览器通过http://localhost/install 访问 Dify 仪表板并开始初始化过程。
参考文档:https://github.com/langgenius/dify
整合与优化
你可以将 Ollama、AnythingLLM 和 Dify 结合起来,形成一个完整的模型管理和部署系统。例如,Ollama 用于下载和管理模型,AnythingLLM 用于本地调用和集成模型,而 Dify 负责模型的 API 部署和管理。
性能优化:根据你的硬件配置,可以尝试使用 GPU 加速(如安装 CUDA 驱动和相关库)来加速推理过程。如果你的机器内存较小,可以考虑在 Docker 中运行模型来减少对系统资源的占用。
安全性和认证:在生产环境中使用模型时,记得为 API 添加认证机制,确保只允许授权用户访问你的服务。
总结
通过 Ollama、AnythingLLM 和 Dify 结合使用,你可以在本地成功搭建和部署 DeepSeek-R1 大语言模型。这个过程不仅帮助你掌握大语言模型的使用,还能够让你通过本地部署享受低延迟、高性能的模型推理体验。根据不同的需求,你可以灵活地调整配置和优化方案,满足个人或团队的需求。
如果你在搭建过程中遇到任何问题,随时可以参考各工具的官方文档,或联系社区进行讨论。希望这篇教程能帮助你顺利完成搭建,开启你的 LLM 之旅!


最新文章



热门文章
-

OpenAI放大招:GPT-4 API,全面开放使用!
: 0.18万 0 -
OpenAI正为ChatGPT测试内容审核功能,可减少人工参与
: 0.18万 0 -
ChatGPT的语言解码奇迹:人类交流的新境界
: 0.17万 0 -
AI首次通过广告图灵测试
: 0.15万 0 -
ChatGPT的追逐战:欲望伴随恐惧
: 0.14万 0 -
本地搭建 DeepSeek-R1 大模型:结合 Ollama、AnythingLLM 和 Dify
: 0.14万 0 -
AI手机是否是手机行业发展的未来?
: 0.13万 0 -
AI写作会不会把真正的作者淘汰掉
: 0.12万 1 -
外媒:OpenAI“草莓”项目曝光,提升AI推理
: 0.11万 0 -
Sora全网爆火,影视行业在瑟瑟发抖?
: 0.11万 0